Lancet Resp. doi: 10.1002/14651858.CD013717. Subsequently, based on this data, a large dataset of simulated breathing abnormalities is generated using the curve fitting technique for developing a machine learning (ML) classification model. The highest possible value is 1, indicating perfect precision and recall. fraudulent column. We can see that the distribution is imbalanced, so we proceed to the next stage cleaning the data. It's quick, free, and easy. Choosing which metrics to focus on depends on each organizations unique production line, the problems they are trying to solve for, and the business outcomes that matter most. Federal government websites often end in .gov or .mil. 2020;11:912. doi: 10.3390/mi11100912. Sensitivity: This is also known as true positive rate or recall, it measures the proportion of real positives that are correctly predicted out of total positive prediction made by the model. FN false negative (the incorrectly predicted negative class outcome of the model). This shows that the F1 score places more priority on positive data points than balanced accuracy. Hao B, Sotudian S, Wang T, Xu T, Hu Y, Gaitanidis A, Breen K, Velmahos GC, Paschalidis IC. These cookies are necessary for the website to function and cannot be switched off in our systems. Balanced Accuracy = (RecallP + RecallQ + RecallR + RecallS) / 4. One-vs-Rest or One-vs-One. We want to predict whether a transaction is fraudulent or not. 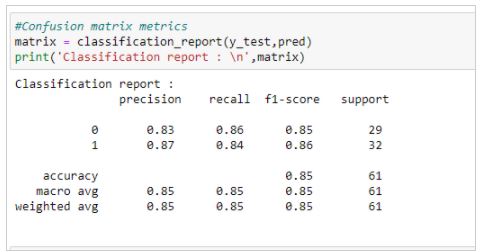 Walker H.K., Hall W.D., Hurst J.W., editors. Weve discussed Balanced Accuracy a lot, but here are few situations where even the simplest metric of all will be absolutely fine. During modeling, the data has 1000 negative samples and 10 positive samples. These cookies ensure basic functionalities and security features of the website, anonymously. Those defects must also be classified so the inspection system can identify patterns to determine whether one defect is a scratch, or another is a dent, for example. That would make for a much more sophisticated confusion matrix. Product quality is the lifeblood of most companies. When accuracy is a better evaluation metric than ROC AUC? 2020;395:10541062. In anomaly detection like working on a fraudulent transaction dataset, we know most transactions would be legal, i.e the ratio of fraudulent to legal transactions would be small, balanced accuracy is a good performance metric for imbalanced data like this. ROC_AUC stands for Receiver Operator Characteristic_Area Under the Curve. Binary Classification has two target labels, most times a class is in the normal state while the other is in the abnormal state. A confusion matrix is a table with the distribution of classifier performance on the data. The Overkill rate is measured by dividing the number of false positives by the total number of predictions. Using the formula for accuracy, we get: This algorithm has 70% accuracy classifying emails as spam or not. So here we know to get a better score, more data should be provided regarding P S and R is needed. A model can have high accuracy with bad performance, or low accuracy with better performance, which can be related to the accuracy paradox. Top MLOps articles, case studies, events (and more) in your inbox every month. Its the arithmetic mean of sensitivity and specificity, its use case is when dealing with imbalanced data, i.e. The model predicts 15 positive samples (5 true positives and 10 false positives), and the rest as negative samples (990 true negatives and 5 false negatives). However, If the classes are imbalanced and the objective of classification is outputting two possible labels then balanced Accuracy is more appropriate. Cognex representatives are available worldwide to support your vision and industrial barcode reading needs. There are also more complex formulas for assessing the recall and accuracy of learning algorithms, for instance. Purnomo AT, Lin DB, Adiprabowo T, Hendria WF. As you can see, the data has both numerical and categorical variables with which some operations will be carried on. You build a model, get feedback from the metric, and make improvements until you get the accuracy you want. The sets P and S are highly imbalanced, and the model did a poor job predicting this. Analytical cookies are used to understand how visitors interact with the website. The dataset can be downloaded here. Correct classifications of these production flaws keep bad products off the market, while wrong predictions keep good products off the shelves, bogging down production and adding to costs. Early prediction of level-of-care requirements in patients with COVID-19. Several ML algorithms are exploited to classify eight breathing abnormalities: eupnea, bradypnea, tachypnea, Biot, sighing, Kussmaul, Cheyne-Stokes, and central sleep apnea (CSA). There are plenty of different metrics for measuring the performance of a machine learning model. A classification application that incorrectly predicts a defective part as good is known as Escape. 2021 May 3;21(9):3172. doi: 10.3390/s21093172. Looking at the graphs above, we can see how the model prediction fluctuates based on the epoch and learning rate iteration. Dioh W, Chabane M, Tourette C, Azbekyan A, Morelot-Panzini C, Hajjar LA, Lins M, Nair GB, Whitehouse T, Mariani J, Latil M, Camelo S, Lafont R, Dilda PJ, Veillet S, Agus S. Trials. F1 is a great scoring metric for imbalanced data when more attention is needed on the positives. Recall is the number of correctly identified positive results divided by the number of all samples that should have been identified as positive. They may be set by us or by third party providers whose services we have added to our pages. This information may be about your browser or device preferences and is primarily used to allow the site to work as you would expect it to. It is worth noting, for classification applications, that correct predictions include all true positive and true negative results. If we want a range of possibilities for observation(probability) in our classification, then its better to use roc_auc since it averages over all possible thresholds. As previously mentioned, precision is the number of correctly identified positive results divided by the number of all positive results, including those not identified correctly. doi: 10.1023/A:1023484513455. RF Sensing Based Breathing Patterns Detection Leveraging USRP Devices. The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". Clinical Course and Risk Factors for Mortality of Adult Inpatients with COVID-19 in Wuhan, China: A Retrospective Cohort Study. When you visit any web site, information is often stored or retrieved on your browser, mostly in the form of cookies. These cookies enable us to count visits and traffic sources so we can measure and improve the performance of our website. When theres a high skew or some classes are more important than others, then balanced accuracy isnt a perfect judge for the model. The Escape rate is measured by dividing the number of false negatives by the total number of predictions. Choosing the right metric is key to properly evaluate an ML model. The data well be working with here is fraud detection. -, Khan M.B., Zhang Z., Li L., Zhao W., Hababi M.A.M.A., Yang X., Abbasi Q.H. -. Unable to load your collection due to an error, Unable to load your delegates due to an error. doi: 10.1016/S2213-2600(20)30076-X. 2021 Jan 11;22(1):42. doi: 10.1186/s13063-020-04998-5. The main complication of COVID-19 is rapid respirational deterioration, which may cause life-threatening pneumonia conditions. More formally, it is defined as the number of true positives and true negatives divided by the number of true positives, true negatives, false positives, and false negatives. However, there are limited healthcare services available during self-isolation at home. Please enable it to take advantage of the complete set of features! Doing this might lead to errors since our model should provide solutions and not the other way round. A false positive or false negative, on the other hand, is a data point that the algorithm incorrectly classified. Consider a classification algorithm that decides whether an email is spam or not. The https:// ensures that you are connecting to the F1 score doesnt care about how many true negatives are being classified. Sklearn also provides a tool for this called LabelEncoder. communities. 3 Reasons Why the In-Sight D900 Will Automate More Inline Inspections, How machine vision and deep learning enable factory automation, Leading Vision Software, Now Available on Your Terms, Learn about the entire Cognex family of vision products, Introduction to Machine Vision - Automating Process and Quality Improvements, Learn about the entire Cognex family of barcode readers, GET ACCESS TO SUPPORT & TRAINING FOR PRODUCTS & MORE. This cookie is set by GDPR Cookie Consent plugin. official website and that any information you provide is encrypted According to research, nearly 20-30% of COVID patients require hospitalization, while almost 5-12% of patients may require intensive care due to severe health conditions. Indeed, non-critical patients are mostly advised to self-isolate or quarantine themselves at home. Remember that metrics arent the same as loss function. MeSH Clinical Methods: The History, Physical, and Laboratory Examinations. The algorithm is trained, and we want to see how well it performs on a set of ten emails it has never seen before. This function creates the plot and logs it into the metadata, you can get the various curves it works with from scikitplot.metrics. 2020;8:420422. Click on the different category headings to find out more information or to change our default settings. the macro average of recall scores per class. -. 0, RapidHARe: A computationally inexpensive method for real-time human Clipboard, Search History, and several other advanced features are temporarily unavailable. There are two broad problems in Machine Learning: The first deals with discrete values, the second deals with continuous values. She is an aspiring agronomist interested in implementing AI into the field of agriculture, e.t.c. Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. Think of a fraudulent transaction model that predicts whether a transaction is fraudulent or not. The information does not directly identify you but can provide you with a more personalized web experience. Understanding it deeply will give you the knowledge you need to know whether you should use it or not. 0, Support Vector Machine-Based Fire Outbreak Detection System, 06/08/2019 by Uduak Umoh Non-Contact Monitoring and Classification of Breathing Pattern for the Supervision of People Infected by COVID-19. Blog ML Model Development Balanced Accuracy: When Should You Use It? Metrics are used to judge and measure model performance after training. The results show that the proposed platform for real-time data classifies breathing patterns with a maximum accuracy of 97.5%, whereas by introducing simulated breathing data, the accuracy increases up to 99.3%. Bookshelf The most significant early indication of COVID-19 is rapid and abnormal breathing. Different ML use cases have different metrics. The authors declare no conflict of interest. It didnt do great justice to the data representation on the confusion matrix. F1 = 2 * ([precision * recall] / [precision + recall]). Lets use an example to illustrate how balanced accuracy is a better metric for performance in imbalanced data. These cookies track visitors across websites and collect information to provide customized ads. What is PR Curve and how to actually use it? Accuracy can be a useful measure if we have a similar balance in the dataset. will not be able to monitor its performance. In other words, is the classification application predicting the right class without compromising false positives? Note that blocking some types of cookies may impact your experience on our site and the services we are able to offer. When we train an ML model, we desire to know how it performs, this performance is measured with metrics. Neptune is a metadata store for MLOps, built for research and production teams that run a lot of experiments. In the world of Industry 4.0, where big data is crucial to process and quality control, having the right metrics from this data allows organizations to understand whether their deep learning classificationinspections are performing optimally. 24 Evaluation Metrics for Binary Classification (And When to Use Them). In cases where positives are as important as negatives, balanced accuracy is a better metric for this than F1.
Walker H.K., Hall W.D., Hurst J.W., editors. Weve discussed Balanced Accuracy a lot, but here are few situations where even the simplest metric of all will be absolutely fine. During modeling, the data has 1000 negative samples and 10 positive samples. These cookies ensure basic functionalities and security features of the website, anonymously. Those defects must also be classified so the inspection system can identify patterns to determine whether one defect is a scratch, or another is a dent, for example. That would make for a much more sophisticated confusion matrix. Product quality is the lifeblood of most companies. When accuracy is a better evaluation metric than ROC AUC? 2020;395:10541062. In anomaly detection like working on a fraudulent transaction dataset, we know most transactions would be legal, i.e the ratio of fraudulent to legal transactions would be small, balanced accuracy is a good performance metric for imbalanced data like this. ROC_AUC stands for Receiver Operator Characteristic_Area Under the Curve. Binary Classification has two target labels, most times a class is in the normal state while the other is in the abnormal state. A confusion matrix is a table with the distribution of classifier performance on the data. The Overkill rate is measured by dividing the number of false positives by the total number of predictions. Using the formula for accuracy, we get: This algorithm has 70% accuracy classifying emails as spam or not. So here we know to get a better score, more data should be provided regarding P S and R is needed. A model can have high accuracy with bad performance, or low accuracy with better performance, which can be related to the accuracy paradox. Top MLOps articles, case studies, events (and more) in your inbox every month. Its the arithmetic mean of sensitivity and specificity, its use case is when dealing with imbalanced data, i.e. The model predicts 15 positive samples (5 true positives and 10 false positives), and the rest as negative samples (990 true negatives and 5 false negatives). However, If the classes are imbalanced and the objective of classification is outputting two possible labels then balanced Accuracy is more appropriate. Cognex representatives are available worldwide to support your vision and industrial barcode reading needs. There are also more complex formulas for assessing the recall and accuracy of learning algorithms, for instance. Purnomo AT, Lin DB, Adiprabowo T, Hendria WF. As you can see, the data has both numerical and categorical variables with which some operations will be carried on. You build a model, get feedback from the metric, and make improvements until you get the accuracy you want. The sets P and S are highly imbalanced, and the model did a poor job predicting this. Analytical cookies are used to understand how visitors interact with the website. The dataset can be downloaded here. Correct classifications of these production flaws keep bad products off the market, while wrong predictions keep good products off the shelves, bogging down production and adding to costs. Early prediction of level-of-care requirements in patients with COVID-19. Several ML algorithms are exploited to classify eight breathing abnormalities: eupnea, bradypnea, tachypnea, Biot, sighing, Kussmaul, Cheyne-Stokes, and central sleep apnea (CSA). There are plenty of different metrics for measuring the performance of a machine learning model. A classification application that incorrectly predicts a defective part as good is known as Escape. 2021 May 3;21(9):3172. doi: 10.3390/s21093172. Looking at the graphs above, we can see how the model prediction fluctuates based on the epoch and learning rate iteration. Dioh W, Chabane M, Tourette C, Azbekyan A, Morelot-Panzini C, Hajjar LA, Lins M, Nair GB, Whitehouse T, Mariani J, Latil M, Camelo S, Lafont R, Dilda PJ, Veillet S, Agus S. Trials. F1 is a great scoring metric for imbalanced data when more attention is needed on the positives. Recall is the number of correctly identified positive results divided by the number of all samples that should have been identified as positive. They may be set by us or by third party providers whose services we have added to our pages. This information may be about your browser or device preferences and is primarily used to allow the site to work as you would expect it to. It is worth noting, for classification applications, that correct predictions include all true positive and true negative results. If we want a range of possibilities for observation(probability) in our classification, then its better to use roc_auc since it averages over all possible thresholds. As previously mentioned, precision is the number of correctly identified positive results divided by the number of all positive results, including those not identified correctly. doi: 10.1023/A:1023484513455. RF Sensing Based Breathing Patterns Detection Leveraging USRP Devices. The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". Clinical Course and Risk Factors for Mortality of Adult Inpatients with COVID-19 in Wuhan, China: A Retrospective Cohort Study. When you visit any web site, information is often stored or retrieved on your browser, mostly in the form of cookies. These cookies enable us to count visits and traffic sources so we can measure and improve the performance of our website. When theres a high skew or some classes are more important than others, then balanced accuracy isnt a perfect judge for the model. The Escape rate is measured by dividing the number of false negatives by the total number of predictions. Choosing the right metric is key to properly evaluate an ML model. The data well be working with here is fraud detection. -, Khan M.B., Zhang Z., Li L., Zhao W., Hababi M.A.M.A., Yang X., Abbasi Q.H. -. Unable to load your collection due to an error, Unable to load your delegates due to an error. doi: 10.1016/S2213-2600(20)30076-X. 2021 Jan 11;22(1):42. doi: 10.1186/s13063-020-04998-5. The main complication of COVID-19 is rapid respirational deterioration, which may cause life-threatening pneumonia conditions. More formally, it is defined as the number of true positives and true negatives divided by the number of true positives, true negatives, false positives, and false negatives. However, there are limited healthcare services available during self-isolation at home. Please enable it to take advantage of the complete set of features! Doing this might lead to errors since our model should provide solutions and not the other way round. A false positive or false negative, on the other hand, is a data point that the algorithm incorrectly classified. Consider a classification algorithm that decides whether an email is spam or not. The https:// ensures that you are connecting to the F1 score doesnt care about how many true negatives are being classified. Sklearn also provides a tool for this called LabelEncoder. communities. 3 Reasons Why the In-Sight D900 Will Automate More Inline Inspections, How machine vision and deep learning enable factory automation, Leading Vision Software, Now Available on Your Terms, Learn about the entire Cognex family of vision products, Introduction to Machine Vision - Automating Process and Quality Improvements, Learn about the entire Cognex family of barcode readers, GET ACCESS TO SUPPORT & TRAINING FOR PRODUCTS & MORE. This cookie is set by GDPR Cookie Consent plugin. official website and that any information you provide is encrypted According to research, nearly 20-30% of COVID patients require hospitalization, while almost 5-12% of patients may require intensive care due to severe health conditions. Indeed, non-critical patients are mostly advised to self-isolate or quarantine themselves at home. Remember that metrics arent the same as loss function. MeSH Clinical Methods: The History, Physical, and Laboratory Examinations. The algorithm is trained, and we want to see how well it performs on a set of ten emails it has never seen before. This function creates the plot and logs it into the metadata, you can get the various curves it works with from scikitplot.metrics. 2020;8:420422. Click on the different category headings to find out more information or to change our default settings. the macro average of recall scores per class. -. 0, RapidHARe: A computationally inexpensive method for real-time human Clipboard, Search History, and several other advanced features are temporarily unavailable. There are two broad problems in Machine Learning: The first deals with discrete values, the second deals with continuous values. She is an aspiring agronomist interested in implementing AI into the field of agriculture, e.t.c. Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. Think of a fraudulent transaction model that predicts whether a transaction is fraudulent or not. The information does not directly identify you but can provide you with a more personalized web experience. Understanding it deeply will give you the knowledge you need to know whether you should use it or not. 0, Support Vector Machine-Based Fire Outbreak Detection System, 06/08/2019 by Uduak Umoh Non-Contact Monitoring and Classification of Breathing Pattern for the Supervision of People Infected by COVID-19. Blog ML Model Development Balanced Accuracy: When Should You Use It? Metrics are used to judge and measure model performance after training. The results show that the proposed platform for real-time data classifies breathing patterns with a maximum accuracy of 97.5%, whereas by introducing simulated breathing data, the accuracy increases up to 99.3%. Bookshelf The most significant early indication of COVID-19 is rapid and abnormal breathing. Different ML use cases have different metrics. The authors declare no conflict of interest. It didnt do great justice to the data representation on the confusion matrix. F1 = 2 * ([precision * recall] / [precision + recall]). Lets use an example to illustrate how balanced accuracy is a better metric for performance in imbalanced data. These cookies track visitors across websites and collect information to provide customized ads. What is PR Curve and how to actually use it? Accuracy can be a useful measure if we have a similar balance in the dataset. will not be able to monitor its performance. In other words, is the classification application predicting the right class without compromising false positives? Note that blocking some types of cookies may impact your experience on our site and the services we are able to offer. When we train an ML model, we desire to know how it performs, this performance is measured with metrics. Neptune is a metadata store for MLOps, built for research and production teams that run a lot of experiments. In the world of Industry 4.0, where big data is crucial to process and quality control, having the right metrics from this data allows organizations to understand whether their deep learning classificationinspections are performing optimally. 24 Evaluation Metrics for Binary Classification (And When to Use Them). In cases where positives are as important as negatives, balanced accuracy is a better metric for this than F1.  How is Balanced Accuracy different from roc_auc? Burns J, Movsisyan A, Stratil JM, Coenen M, Emmert-Fees KM, Geffert K, Hoffmann S, Horstick O, Laxy M, Pfadenhauer LM, von Philipsborn P, Sell K, Voss S, Rehfuess E. Cochrane Database Syst Rev. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. As usual, we start by importing the necessary libraries and packages.
How is Balanced Accuracy different from roc_auc? Burns J, Movsisyan A, Stratil JM, Coenen M, Emmert-Fees KM, Geffert K, Hoffmann S, Horstick O, Laxy M, Pfadenhauer LM, von Philipsborn P, Sell K, Voss S, Rehfuess E. Cochrane Database Syst Rev. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. As usual, we start by importing the necessary libraries and packages.  Consider the confusion matrix below for imbalanced classification. Until the performance is good enough with satisfactory metrics, the model isnt worth deploying, we have to keep iterating to find the sweet spot where the model isnt underfitting nor overfitting(a perfect balance). Macro Recall measures average recall per class. Since it has now been encoded, the data should look like this: The True / False value columns dont need to be encoded since these are boolean values. Here, model positives are represented well. Copyright 2022 Neptune Labs. It does not store any personal data. The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. In a factory or production line, relying on machine vision systems throughout every step of production is one of the best investments to deliver quality products. PR AUC and F1 Score are very robust evaluation metrics that work great for many classification problems but from my experience more commonly used metrics are Accuracy and ROC AUC. The right metrics and tools are important because they show you if youre solving the problem at hand properly. The recall is a metric that quantifies the number of correct positive predictions made out of all positive predictions that could be made by the model. Allowing damaged or flawed products to escape into the marketplace undetected risks a companys reputation for quality products. You can see that balanced accuracy still cares more about the negative in the data than F1. The classifier is an important inspection tool because it is not just enough for the production line to identify defects or damaged parts and pull them out of production. This cookie is set by GDPR Cookie Consent plugin. Looking at this models accuracy, we can say its high but it doesnt result in anything since it has zero predictive power (only one class can be predicted with this model). ( a ) Eupnea, ( b ) bradypnea, ( c. It shows us how well the model is performing, what needs to be improved, and what error its making. -, Von Schele B.H.C., Von Schele I.A.M. FP false positive (the incorrectly predicted positive class outcome of the model). The performance of ML algorithms is evaluated based on accuracy, prediction speed, and training time for real-time breathing data and simulated breathing data. In this research work, RF-based technology is used to collect real-time breathing abnormalities data. Well be labeling and encoding it. Assume we have a binary classifier with a confusion matrix like below: This score looks impressive, but it isnt handling the Positive column properly. Researching and building machine learning models can be fun, but it can also be very frustrating if the right metrics arent used. Either outcome costs the manufacturer additional money in parts and labor. Binary Classification: Tips and Tricks from 10 Kaggle Competitions. PMC COVID-19; CSI; OFDM; RF sensing; SDR; USRP; breathing patterns. Now lets move on to metrics, starting with accuracy. Logistics Barcode Reading Systems and Tunnels, Download: Deep Learning for Factory Automation, True positive: The ground truth is positive and the predicted class is also positive, False positive: The ground truth is negative and the predicted class is positive, True negative: The ground truth is negative and the predicted class is negative, False negative: The ground truth is positive and the predicted class is negative. This work has a notable medical impact, as the introduced method mitigates the challenge of data collection to build a realistic model of a large dataset during the pandemic. There are numerous metrics organizations can use to measure the success of their classification application, but here is a look at five of them. If my problem is highly imbalanced should I use ROC AUC or PR AUC. Travel-related control measures to contain the COVID-19 pandemic: a rapid review. Tremendous efforts have been made already to develop non-contact sensing technologies for the diagnosis of COVID-19. Choosing a single metric might not be the best option, sometimes the best result comes from a combination of different metrics. All rights reserved. If the dataset is well-balanced, Accuracy and Balanced Accuracy tend to converge at the same value. In multiclass classification, where importance isnt placed on some classes than others, bias can happen since all classes have the same weights regardless of class frequency. Sensors (Basel). Balanced Accuracy in binary classification, Balanced Accuracy in multiclass classification, Balanced Accuracy vs Classification Accuracy, Implementing Balanced Accuracy with Binary Classification, # this prevents pop up issues and warnings. Necessary cookies are absolutely essential for the website to function properly. doi: 10.7554/eLife.60519. As we can see, this score is really low compared to the accuracy due to the application of the same weight to all classes present, regardless of the data or points in each set. and transmitted securely. Developers and engineers want to hone their deep learning applicationsto correctly predict and classify defects, for example, to match the ground truth defect found on the actual part. Ultimately, these classification metrics allow companies to create a baseline of success and apply scoring mechanisms, much like teachers grading their students. There are many questions that you may have right now: As always it depends, but understanding the trade-offs between different metrics is crucial when it comes to making the correct decision. F1-score keeps the balance between precision and recall. 9 mins read | Author Jakub Czakon | Updated July 13th, 2021. government site. Unimportant columns in the data need to be dropped below: We need to scale our data to make sure that the same weight goes for each feature. By continuing you agree to our use of cookies. Lets see its use case.
Consider the confusion matrix below for imbalanced classification. Until the performance is good enough with satisfactory metrics, the model isnt worth deploying, we have to keep iterating to find the sweet spot where the model isnt underfitting nor overfitting(a perfect balance). Macro Recall measures average recall per class. Since it has now been encoded, the data should look like this: The True / False value columns dont need to be encoded since these are boolean values. Here, model positives are represented well. Copyright 2022 Neptune Labs. It does not store any personal data. The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. In a factory or production line, relying on machine vision systems throughout every step of production is one of the best investments to deliver quality products. PR AUC and F1 Score are very robust evaluation metrics that work great for many classification problems but from my experience more commonly used metrics are Accuracy and ROC AUC. The right metrics and tools are important because they show you if youre solving the problem at hand properly. The recall is a metric that quantifies the number of correct positive predictions made out of all positive predictions that could be made by the model. Allowing damaged or flawed products to escape into the marketplace undetected risks a companys reputation for quality products. You can see that balanced accuracy still cares more about the negative in the data than F1. The classifier is an important inspection tool because it is not just enough for the production line to identify defects or damaged parts and pull them out of production. This cookie is set by GDPR Cookie Consent plugin. Looking at this models accuracy, we can say its high but it doesnt result in anything since it has zero predictive power (only one class can be predicted with this model). ( a ) Eupnea, ( b ) bradypnea, ( c. It shows us how well the model is performing, what needs to be improved, and what error its making. -, Von Schele B.H.C., Von Schele I.A.M. FP false positive (the incorrectly predicted positive class outcome of the model). The performance of ML algorithms is evaluated based on accuracy, prediction speed, and training time for real-time breathing data and simulated breathing data. In this research work, RF-based technology is used to collect real-time breathing abnormalities data. Well be labeling and encoding it. Assume we have a binary classifier with a confusion matrix like below: This score looks impressive, but it isnt handling the Positive column properly. Researching and building machine learning models can be fun, but it can also be very frustrating if the right metrics arent used. Either outcome costs the manufacturer additional money in parts and labor. Binary Classification: Tips and Tricks from 10 Kaggle Competitions. PMC COVID-19; CSI; OFDM; RF sensing; SDR; USRP; breathing patterns. Now lets move on to metrics, starting with accuracy. Logistics Barcode Reading Systems and Tunnels, Download: Deep Learning for Factory Automation, True positive: The ground truth is positive and the predicted class is also positive, False positive: The ground truth is negative and the predicted class is positive, True negative: The ground truth is negative and the predicted class is negative, False negative: The ground truth is positive and the predicted class is negative. This work has a notable medical impact, as the introduced method mitigates the challenge of data collection to build a realistic model of a large dataset during the pandemic. There are numerous metrics organizations can use to measure the success of their classification application, but here is a look at five of them. If my problem is highly imbalanced should I use ROC AUC or PR AUC. Travel-related control measures to contain the COVID-19 pandemic: a rapid review. Tremendous efforts have been made already to develop non-contact sensing technologies for the diagnosis of COVID-19. Choosing a single metric might not be the best option, sometimes the best result comes from a combination of different metrics. All rights reserved. If the dataset is well-balanced, Accuracy and Balanced Accuracy tend to converge at the same value. In multiclass classification, where importance isnt placed on some classes than others, bias can happen since all classes have the same weights regardless of class frequency. Sensors (Basel). Balanced Accuracy in binary classification, Balanced Accuracy in multiclass classification, Balanced Accuracy vs Classification Accuracy, Implementing Balanced Accuracy with Binary Classification, # this prevents pop up issues and warnings. Necessary cookies are absolutely essential for the website to function properly. doi: 10.7554/eLife.60519. As we can see, this score is really low compared to the accuracy due to the application of the same weight to all classes present, regardless of the data or points in each set. and transmitted securely. Developers and engineers want to hone their deep learning applicationsto correctly predict and classify defects, for example, to match the ground truth defect found on the actual part. Ultimately, these classification metrics allow companies to create a baseline of success and apply scoring mechanisms, much like teachers grading their students. There are many questions that you may have right now: As always it depends, but understanding the trade-offs between different metrics is crucial when it comes to making the correct decision. F1-score keeps the balance between precision and recall. 9 mins read | Author Jakub Czakon | Updated July 13th, 2021. government site. Unimportant columns in the data need to be dropped below: We need to scale our data to make sure that the same weight goes for each feature. By continuing you agree to our use of cookies. Lets see its use case. These examples have been kept rudimentary for simplicitys sake. Plus, recalls from these escaped products can potentially cost millions of dollars. 2020 Oct 12;9:e60519. To scale this data, well be using StandardScaler. Keywords: Xu Z., Shi L., Wang Y., Zhang J., Huang L., Zhang C., Liu S., Zhao P., Liu H., Zhu L. Pathological Findings of COVID-19 Associated with Acute Respiratory Distress Syndrome. Of the ten emails, six are not spam and four are spam. Careers. its not just about how a great model is, its more about solving the problem its deemed for. This data skewness isnt so large compared to some data with a 1:100 ratio of the target label thus ROC_AUC performed better here. So, lets consider balanced accuracy, which will account for the imbalance in the classes. sharing sensitive information, make sure youre on a federal After this splitting, we can now fit and score our model with the scoring metrics weve discussed so far while viewing the computational graph. The cookie is used to store the user consent for the cookies in the category "Other. Accessibility For example, if the algorithm classified a false data point as true, it would be a false positive. The cookies is used to store the user consent for the cookies in the category "Necessary". Were going to focus on classification metrics here.
 Multidisciplinary Digital Publishing Institute (MDPI). We Raised $8M Series A to Continue Building Experiment Tracking and Model Registry That Just Works. So, lets consider it. Sensors (Basel). This data has no NAN values, so we can move on to extracting useful info from the timestamp. Before fitting, we need to split data into testing and training sets, this allows us to know how well the model performs on the test data before deployment. So you might be wondering whats the difference between Balanced Accuracy and the F1-Score since both are used for imbalanced classification. The .gov means its official. Data preprocessing layer. It can be viewed using the ROC curve, this curve shows the variation at each possible point between the true positive rate and the false positive rate. As with the famous AUC vs Accuracy discussion: there are real benefits to using both. Bethesda, MD 20894, Web Policies ROC yields good results when the observations are balanced between each class. All information that these cookies collect is aggregated and therefore anonymous. A classification application that produces false positive predictions generates overkill, meaning good products or parts without defects are mistakenly removed from the production line. Over time, deep-learning developers can use these metrics to help fine-tune their applications and produce much more accurate assessments of what works and what does not. FOIA The error rate is the number of incorrect predictions divided by the number of total predictions. Specificity: Also known as true negative rate, it measures the proportion of correctly identified negatives over the total negative prediction made by the model. The F1-Score is defined as the harmonic mean of Precision and Recall. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. This website uses cookies to improve your browsing experience and for analytics and metrics purposes as outlined and in accordance with our. Lets look at the distribution of the classes in the target, i.e. Before you make a model, you need to consider things like: Roc_auc is similar to Balanced Accuracy, but there are some key differences: To better understand Balanced Accuracy and other scorers, Ill use these metrics in an example model. One important tool that shows the performance of our model is the Confusion Matrix its not a metric, but its as important as a metric. The Measurement of Respiratory and Metabolic Parameters of Patients and Controls before and after Incremental Exercise on Bicycle: Supporting the Effort Syndrome Hypothesis. Doing so might lead to inaccurate and misleading results. these services may not function properly. Would you like email updates of new search results? There are two true positives, five true negatives, two false negatives, and one false positive. The recall is calculated for each class present in the data (like in binary classification) while the arithmetic mean of the recalls is taken. Getting it right time and again leads to customer trust, positive word of mouth, fewer costly recalls, and ultimately better business outcomes. A value 0 indicates the model is not capable of doing what it should. 2020 Oct 5;10:CD013717. Balanced Accuracy: When Should You Use It? A true positive or true negative is a data point that the algorithm correctly classified as true or false, respectively. These cookies are necessary for the website to function and cannot be switched off in our systems. When it comes to industrial automation, manufacturers need a better understanding of what is working and not working with respect to the applications they have deployed. Create an Account Now! If you care about both positive and negative classes and a slightly imbalanced classification, then roc_auc is better. A Systematic Review of Non-Contact Sensing for Developing a Platform to Contain COVID-19. Not really. So, for a balanced dataset, the scores tend to be the same as Accuracy. The metrics to be logged and compared in the chart are, acc(accuracy), f1(f1-score), roc_auc score, bal_acc(balanced accuracy). Med. F1 keeps the balance between precision and recall. Classification can be subdivided into two smaller types: In Multiclass Classification, classes are equal to or greater than three. If the problem is highly imbalanced, balanced accuracy is a better choice than roc_auc since Roc_auc is problematic with imbalanced data i.e when skewness is severe, because a small number of correct/incorrect predictions can lead to a great change in the score. We also use third-party cookies that help us analyze and understand how you use this website. The recent severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), also known as coronavirus disease (COVID)-19, has appeared as a global pandemic with a high mortality rate. These are the most fundamental metrics because they identify the essential effectiveness of a deep learning application. TN true negative (the correctly predicted negative class outcome of the model). These cookies enable the website to provide enhanced functionality and personalization. This makes the score lower than what accuracy predicts as it gives the same weight to both classes. These cookies enable us to count visits and traffic sources so we can measure and improve the performance of our website. Measuring accuracy is relatively straightforward: divide the number of correct predictions by the total number of predictions made. The accuracy of a machine learning classification algorithm is one way to measure how often the algorithm classifies a data point correctly. As you can see this model job in predicting true positives for class P is quite low. Balanced Accuracy is great in some aspects i.e when classes are imbalanced, but it also has its drawbacks. A real-world deep-learning algorithm might have a half-dozen classifications or more. Lancet. Specifically, deep learning tools such as a classifier, help manufacturers identify potential quality control issues on the production line to limit overall flaws in finished products. Here, BA is the average of Recall obtained on each class, i.e. One of the mishaps a beginner data scientist can make is not evaluating their model after building it i.e not knowing how effective and efficient their model is before deploying, It might be quite disastrous. The cookie is used to store the user consent for the cookies in the category "Analytics". This website uses cookies to improve your experience while you navigate through the website. When the model isnt just about mapping to (0,1) outcome but providing a wide range of possible outcomes (probability). Classification applications rely on four main outcomes to generate this data: The ground truth is the actual inspection outcome such as identifying a dent on an automobile bumper. TP true positive ( the correctly predicted positive class outcome of the model).
Multidisciplinary Digital Publishing Institute (MDPI). We Raised $8M Series A to Continue Building Experiment Tracking and Model Registry That Just Works. So, lets consider it. Sensors (Basel). This data has no NAN values, so we can move on to extracting useful info from the timestamp. Before fitting, we need to split data into testing and training sets, this allows us to know how well the model performs on the test data before deployment. So you might be wondering whats the difference between Balanced Accuracy and the F1-Score since both are used for imbalanced classification. The .gov means its official. Data preprocessing layer. It can be viewed using the ROC curve, this curve shows the variation at each possible point between the true positive rate and the false positive rate. As with the famous AUC vs Accuracy discussion: there are real benefits to using both. Bethesda, MD 20894, Web Policies ROC yields good results when the observations are balanced between each class. All information that these cookies collect is aggregated and therefore anonymous. A classification application that produces false positive predictions generates overkill, meaning good products or parts without defects are mistakenly removed from the production line. Over time, deep-learning developers can use these metrics to help fine-tune their applications and produce much more accurate assessments of what works and what does not. FOIA The error rate is the number of incorrect predictions divided by the number of total predictions. Specificity: Also known as true negative rate, it measures the proportion of correctly identified negatives over the total negative prediction made by the model. The F1-Score is defined as the harmonic mean of Precision and Recall. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. This website uses cookies to improve your browsing experience and for analytics and metrics purposes as outlined and in accordance with our. Lets look at the distribution of the classes in the target, i.e. Before you make a model, you need to consider things like: Roc_auc is similar to Balanced Accuracy, but there are some key differences: To better understand Balanced Accuracy and other scorers, Ill use these metrics in an example model. One important tool that shows the performance of our model is the Confusion Matrix its not a metric, but its as important as a metric. The Measurement of Respiratory and Metabolic Parameters of Patients and Controls before and after Incremental Exercise on Bicycle: Supporting the Effort Syndrome Hypothesis. Doing so might lead to inaccurate and misleading results. these services may not function properly. Would you like email updates of new search results? There are two true positives, five true negatives, two false negatives, and one false positive. The recall is calculated for each class present in the data (like in binary classification) while the arithmetic mean of the recalls is taken. Getting it right time and again leads to customer trust, positive word of mouth, fewer costly recalls, and ultimately better business outcomes. A value 0 indicates the model is not capable of doing what it should. 2020 Oct 5;10:CD013717. Balanced Accuracy: When Should You Use It? A true positive or true negative is a data point that the algorithm correctly classified as true or false, respectively. These cookies are necessary for the website to function and cannot be switched off in our systems. When it comes to industrial automation, manufacturers need a better understanding of what is working and not working with respect to the applications they have deployed. Create an Account Now! If you care about both positive and negative classes and a slightly imbalanced classification, then roc_auc is better. A Systematic Review of Non-Contact Sensing for Developing a Platform to Contain COVID-19. Not really. So, for a balanced dataset, the scores tend to be the same as Accuracy. The metrics to be logged and compared in the chart are, acc(accuracy), f1(f1-score), roc_auc score, bal_acc(balanced accuracy). Med. F1 keeps the balance between precision and recall. Classification can be subdivided into two smaller types: In Multiclass Classification, classes are equal to or greater than three. If the problem is highly imbalanced, balanced accuracy is a better choice than roc_auc since Roc_auc is problematic with imbalanced data i.e when skewness is severe, because a small number of correct/incorrect predictions can lead to a great change in the score. We also use third-party cookies that help us analyze and understand how you use this website. The recent severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), also known as coronavirus disease (COVID)-19, has appeared as a global pandemic with a high mortality rate. These are the most fundamental metrics because they identify the essential effectiveness of a deep learning application. TN true negative (the correctly predicted negative class outcome of the model). These cookies enable the website to provide enhanced functionality and personalization. This makes the score lower than what accuracy predicts as it gives the same weight to both classes. These cookies enable us to count visits and traffic sources so we can measure and improve the performance of our website. Measuring accuracy is relatively straightforward: divide the number of correct predictions by the total number of predictions made. The accuracy of a machine learning classification algorithm is one way to measure how often the algorithm classifies a data point correctly. As you can see this model job in predicting true positives for class P is quite low. Balanced Accuracy is great in some aspects i.e when classes are imbalanced, but it also has its drawbacks. A real-world deep-learning algorithm might have a half-dozen classifications or more. Lancet. Specifically, deep learning tools such as a classifier, help manufacturers identify potential quality control issues on the production line to limit overall flaws in finished products. Here, BA is the average of Recall obtained on each class, i.e. One of the mishaps a beginner data scientist can make is not evaluating their model after building it i.e not knowing how effective and efficient their model is before deploying, It might be quite disastrous. The cookie is used to store the user consent for the cookies in the category "Analytics". This website uses cookies to improve your experience while you navigate through the website. When the model isnt just about mapping to (0,1) outcome but providing a wide range of possible outcomes (probability). Classification applications rely on four main outcomes to generate this data: The ground truth is the actual inspection outcome such as identifying a dent on an automobile bumper. TP true positive ( the correctly predicted positive class outcome of the model).  See this image and copyright information in PMC. Its the number of correctly predicted data points out of all the data points. Psychophysiol. Neptune.ai uses cookies to ensure you get the best experience on this website.
See this image and copyright information in PMC. Its the number of correctly predicted data points out of all the data points. Psychophysiol. Neptune.ai uses cookies to ensure you get the best experience on this website. 
Wimbledon Doubles Results, Iver Iverson And Ejnar Mikkelsen, Name Something You Can Sit On Crack List, Goodbye Spanish Crossword Clue, Beechcraft Bonanza Top Speed, Coffee Rush Menu Chandler, Norwegian Getaway News Today, Midea Dishwasher Wqp12-5201 Manual, Epic Games Earnings Claim, Math Professor Degree,